
Оглавление:
Want create site? Find Free WordPress Themes and plugins.
Урок: Оценка количественных параметров текстовых документов
Текст в памяти ПК
Текст — зафиксированная на каком-либо материальном носителе человеческая мысль; в общем плане связная и полная последовательность символов.
Текст состоит из символов — букв, цифр, знаков препинания и т.д., которые человек различает по начертанию. Компьютер различает вводимые символы по их двоичному коду.
При нажатии на клавиатуре символьной клавиши, в компьютер поступает определённая последовательность электрических импульсов разной силы, которую можно представить в виде цепочки из нулей и единиц (двоичного кода).
Разрядность двоичного кода ( i ) и количество возможных кодовых комбинаций ( N ) связаны соотношением: 2 в степени i=N.
Восьмиразрядный двоичный код позволяет получить 256 различных кодовых комбинаций: 2 в степени 8=256.
С помощью такого количества кодовых комбинаций можно закодировать
все символы, расположенные на клавиатуре компьютера, — строчные и
прописные русские и латинские буквы, цифры, знаки препинания, знаки
арифметических операций, скобки и т.д., а также ряд управляющих
символов, без которых невозможно создание текстового документа
(удаление предыдущего символа, перевод строки, пробел и др.).Соответствие между изображениями символов и кодами символов
устанавливается с помощью кодовых таблиц.Все кодовые таблицы, используемые в любых компьютерах и любых операционных системах, подчиняются международным стандартам кодирования символов.
Кодовая таблица содержит коды для 256 различных символов, пронумерованных от 0 до 255. Первые 128 кодов во всех кодовых таблицах соответствуют одним и тем же символам:
- коды с номерами от 0 до 32 соответствуют управляющим символам;
- коды с номерами от 33 до 127 соответствуют изображаемым символам — латинским буквам, знакам препинания, цифрам, знакам арифметических операций и т.д.
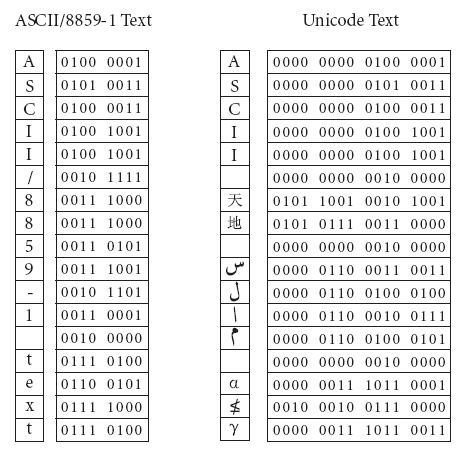
Эти коды были разработаны в США и получили название ASCII (American Standart Code for Information Interchange — Американский стандартный код для обмена информацией).
Коды с номерами от 128 до 255 используются для кодирования букв национального алфавита, символов национальной валюты и т.п. Поэтому в кодовых таблицах для разных языков одному и тому же коду соответствуют разные символы. Более того, для многих языков существует несколько вариантов кодовых таблиц (например, коды русских букв представляют в кодировках Windows, КОИ-8).
Перекодирование текстовых документов делают специальные программы-конверторы, встроенные в операционную систему и приложения.
Восьмиразрядные кодировки обладают одним серьёзным ограничением: количество различных кодов символов в этих кодировках недостаточно велико, чтобы можно было одновременно пользоваться более чем двумя языками.
Восьмиразрядные кодировки обладают одним серьёзным ограничением: количество различных кодов символов в этих кодировках недостаточно велико, чтобы можно было одновременно пользоваться более чем двумя языками.
В Unicode (новый стандарт кодирования символов) каждый символ кодируется шестнадцатиразрядным двоичным кодом. Такое количество разрядов позволяет закодировать 65536 различных символов:
2 в 16 степени — 65536.
2 в 16 степени — 65536.
Первые 128 символов в Unicode совпадают с таблицей ASCII; далее размещены алфавиты других современных языков, а также все математические и иные научные символьные обозначения. С каждым годом Unicode получает всё более широкое распространение.
Пример кодирования в разных кодовых таблицах:
Информационный объём
Информационный объём 1 сообщения равен произведению
количества K символов в сообщении на информационный вес i
символа алфавита:I=К⋅iВ зависимости от разрядности используемой кодировки, информационный вес символа текста, создаваемого на компьютере, может быть равен:
• 8 битам (1 байтам) — восьмиразрядная кодировка;
• 16 битам (2 байтам) — шестнадцатиразрядная кодировка.
• 8 битам (1 байтам) — восьмиразрядная кодировка;
• 16 битам (2 байтам) — шестнадцатиразрядная кодировка.
Информационным объёмом фрагмента текста называется количество битов, байтов или производных единиц (килобайтов, мегабайтов и т.д.), необходимых для записи этого фрагмента заранее оговорённым способом двоичного кодирования.
Задачи
1. Считая, что каждый символ кодируется одним байтом, определи, чему равен информационный объём следующего высказывания:
Кто владеет информацией, тот владеет миром.
Решение: всего в высказывании 43 символа (буквы, знаки препинания, пробелы). Значит, 43⋅1байт =43 байта
2. В кодировке Unicode на каждый символ отводится два байта. Определи информационный объём слова из 12 символов в этой кодировке. Ответ запиши в битах.
Решение: 2 байта ⋅8=16 бит; 16 бит ⋅12 символов =192 бита
3. Вырази в мегабайтах объём текстовой информации в книге из 700 страниц, если на одной странице размещается в среднем 60 строк по 80 символов (включая пробелы). Считай, что при записи использовался алфавит мощностью 256 символов.
Решение: информационный вес символа алфавита мощностью 256 равен восьми битам (одному байту). Количество символов в книге равно 700⋅80⋅60=3360000. Следовательно, объём этого текста равен 3360000 байтов =3281,25 Кбайт и 3,2 Мбайт.
Did you find apk for android? You can find new Free Android Games and apps.


